Learn Before
Batch Gradient Descent Update Formula
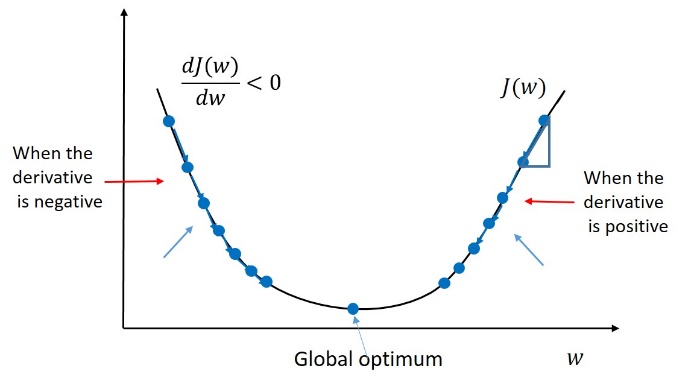
Assuming that the error function is with one parameter , to minimize the error, we can update the weight as follows:
where is the learning rate, and is the derivative of with respect to . If the error function has two or more parameters, for example, a weight and a bias , we can update them one by one:
where denotes the partial derivative.
0
2
Contributors are:




Who are from:


Tags
Data Science
Related
Gradient Descent Reference
Linear Regression and Gradient Descent
Numerical Approximation of Gradients
Gradient Checking
Gradient Descent Explained
Why Gradient descent might fail?
A Chat with Andrew on MLOps: From Model-centric to Data-centric AI
Big Data to Good Data: Andrew Ng Urges ML Community To Be More Data-Centric and Less Model-Centric
MLOps: Data-centric and Model-centric approaches
Critical Points
First-order Optimization Algorithm
Method of Steepest Descent
Second-Order Gradient Methods
Gradient Descent Explanation
Gradient Descent Variants
Notes about gradient descent
Suppose you have built a neural network. You decide to initialize the weights and biases to be zero. Which of the following statements is true?
Vanishing/exploding gradient
BERT Training Process
Objective Function
Distributed Training
The Problem with Constant Initialization
Objective Function Change Bounds in Gradient Descent
One-Dimensional Gradient Descent
Multivariate Gradient Descent
Second-Order Optimization Algorithm
Average Objective Function in Deep Learning
Accelerated Gradient Methods
Batch Gradient Descent Update Formula
Learn After
Derivation of the Gradient Descent Formula
Mini-Batch Gradient Descent
Epoch in Gradient Descent
Gradient Descent with Momentum
For logistic regression, the gradient is given by ∂∂θjJ(θ)=1m∑mi=1(hθ(x(i))−y(i))x(i)j. Which of these is a correct gradient descent update for logistic regression with a learning rate of α?
Suppose you have the following training set, and fit a logistic regression classifier .
Backpropagation
Batch vs Stochastic vs Mini-Batch Gradient Descent
Logistic Regression Gradient Descent Derivation