Learn Before
Concept
Input to LAS
The input of LAS is a sequence of acoustic feature vectors where one vector is spanning each frame of 10 milliseconds. Assuming the output as letters, the output sequence Y = (langle SOS rangle, y_1, ..., y_m ,langle EOS rangle), assuming each langle SOS rangle to be a special start. ofspeech token and each langle EOS rangle to be a special end of speech token. The following image shows the set we might select for the output if we are considering the English language
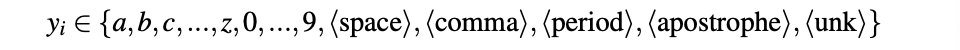
0
1
Updated 2022-05-08


Tags
Deep Learning (in Machine learning)
Data Science